The Will To Understand
Why I am not interested in using AI in my intellectual and creative practice
If a system is to serve the creative spirit, it must be entirely comprehensible to a single individual. The point here is that the human potential manifests itself in individuals. To realize this potential, we must provide a medium that can be mastered by a single individual. Any barrier that exists between the user and some part of the system will eventually be a barrier to creative expression.
I took up drawing just as Silicon Valley told me my skill would be rendered irrelevant. I entered the professional field of machine learning just as I was told deep learning would revolutionize the scientific process. In both cases I have not allowed my own ambitions to be cowed by the pageantry surrounding the tech industry's shiny new toy, and have instead tried to preserve a path that preserves my own ability to understand and learn, even when aided by the machine.
I offer here some thoughts about why generative AI does not really address the types of questions and work that drew me to programming and art, respectively, in the first place.
Learning to see

In my professional career, I have avoided the use of deep learning for many tasks because I am cursed to understand why it works, and that is frequently a fool's errand that, if it is possible at all, takes an order of magnitude longer than merely achieving a high level of predictive accuracy with a deep learning-based classifier or model.
There are many tasks where predictive accuracy may trump the need for simple closed-form models and even interpretability to some degree. A good collection of examples and arguments in favor of a 'prediction first' approach that anticipates the development of modern data science is given by Leo Breiman in the classic paper Statistical Modeling: The Two Cultures. In such contexts, deep learning may very well be the correct tool to use. However, as someone with the pretensions of a social scientist, I am personally not as interested in those questions. Thus, 'classical' machine learning techniques like decision trees and generalized linear models are much more appealing to me. They can still frequently outperform their more opaque competitors, and I can much better see the relationships between the input variables and the response variable - and hopefully learn something about the real world in the process.
Similarly, in the domain of art, I learn nothing from a vague prompt that I poke with words until it looks even more vaguely satisfactory. By trying, and failing, to see the masses and edges of a tree, I learn much more. I learn how to draw a consistent line, how to simplify an object based on its distance to me and the light falling on it, and how to quickly make different types of tree visually distinct to a viewer at a glance.
My knowledge and ability grows, unmediated by a company's need to surveil my own creative "process" to extract information from it that they will attempt to use to replace me. I learn from the knowledge of others in a genuinely social way - by observing a teacher and having my own work observed - not through the ersatz sociality of an agglomeration of mediocrity vacuumed up from the internet.
In short, I have control over what I do. I immediately see the result of placing each individual line in the right place. I don't have to pray the rest o the image remains the same when I just want to change one aspect of the lighting.
Whatever simulacrum of "inpainting" exists in stable diffusion requires the type of endless parameter tweaking that I seek escape from when I draw!

It is "painting" in the same sense that "machine learning" is "learning": a highly error-prone process that requires patiently waiting for your batch job to run after tweaking some parameters, so that the machine can eventually get all of the credit for success while you assume blame for its failures. This process bears absolutely no resemblance to the way I want to work. Such stunning technical ability put to the purpose of, once again, 'blindly manipulating symbols,' even in an ostensibly visual domain.
Even the most advanced models have the explicit caveat that the central concern of art, at every level of skill - composition - is beyond the model's reach: The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to 'A red cube on top of a blue sphere.'
I don't learn to see by using Stable Diffusion. I learn not to see.
(YA)MLops
As I alluded to above, working with opaque ML systems is frequently not enjoyable. The initial thrill of feeling like you've cracked the problem or gotten an acceptable level of predictable accuracy quickly gives way to bureaucratic tedium. You have a very brittle process that requires constant monitoring, tinkering, and instrumentation to make sure you're not facing performance regressions.
Most of this monitoring isn't well-supported within the actual programming context, so you have to reach outside your programming language of choice for a half-baked wrapper atop a database that lets you remember what your parameters are. You end up declare all the components of your workflow in a plaintext environment where composition is impossible, consistency is not enforced, and you have no query capabilities - often in a format like YAML, which I have previously criticized.
These difficulties are intrinsic to ML systems, and you don't have to take my word on that. Several researchers at Google were uniquely well-suited to identify the difficulties in building and maintaining ML systems that perform useful work in the real world, and they described them quite well nearly a decade ago in the paper "Machine Learning: The High-Interest Credit Card of Technical Debt." The paper identifies several sources of debt: data debt, pipeline debt, and configuration debt that are likely to impose very high maintenance burdens on anyone working with ML systems. If the proposed design of LLM-based systems is any indication, the interest rate on the LLM credit card is substantially higher than the ML card.
Anyone thinking of ascending the mountain of madness specified in Andressen Horowitz's work of speculative fiction "Emerging Architectures for LLMs" should read through this paper several times and ask themselves if they are prepared for the journey, and what they expect to find at its conclusion.

One of the reasons I enjoy programming is because, when I do it well, I can directly map my conceptual representations of a problem to components in the code, thus achieving an organizational structure that suits both myself as the maintainer of the system and the machine the system runs on. I like to half-jokingly refer to this as "applied metaphysics." With prompt-based language models as an important component of software, such a conceptual and practical separation of concerns is impossible. Everything is just text.
Every integration, so far, of a language model with a larger production system involved jamming the control prompt, provided by the developer, and the input, provided by the end-user, together and schlepping it over to the language model that interprets it as a single text.
The control prompt usually included language that tells the model not to listen to control statements in the input, but because it’s all input into the model as one big slop, there’s nothing really to prevent an adversarial end-user from finding ways to countermand the commands in the developer portion of the prompt.
Bjarnason correctly identifies this as a major security issue, because attackers can exploit parts of the prompts as an arbitrary "control surface," but I believe it is much broader than that. The fact that all signals in the LLM component of the system are just strings means that there can be no "separation of concerns", whereby only the information necessary to perform a specific task is conveyed from one subsystem to another. If the program uses a language model to perform multiple different tasks, they could easily mix with one another. Imagine injecting non-determinism and the potential for noise into every stack frame executed by your program and you can get an idea of what it might be like to program with LLMs for an extended period of time.
The difficulty was anticipated by the authors of the Google Research paper:
From a high level perspective, a machine learning package is a tool for mixing data sources together. That is, machine learning models are machines for creating entanglement and making the isolation of improvements effectively impossible. To make this concrete, imagine we have a system that uses features x1, ...xn in a model. If we change the input distribution of values in x1, the importance, weights, or use of the remaining n − 1 features may all change—this is true whether the model is retrained fully in a batch style or allowed to adapt in an online fashion. Adding a new feature xn+1 can cause similar changes, as can removing any feature xj. No inputs are ever really independent. We refer to this here as the CACE principle: Changing Anything Changes Everything. The net result of such changes is that prediction behavior may alter, either subtly or dramatically, on various slices of the distribution. The same principle applies to hyper-parameters. Changes in regularization strength, learning settings, sampling methods in training, convergence thresholds, and essentially every other possible tweak can have similarly wide ranging effects.
I may have a strong preference for dynamically-typed languages, but I still appreciate that I get an exception when I try to increment a string. With LLMs, everything is a string. And therefore there's no way to enforce meaningful boundaries between good and bad inputs:

This non-locality appears to be a fundamental flaw that bleeds into every aspect of generative AI systems as they currently exist, including image synthesis tools.
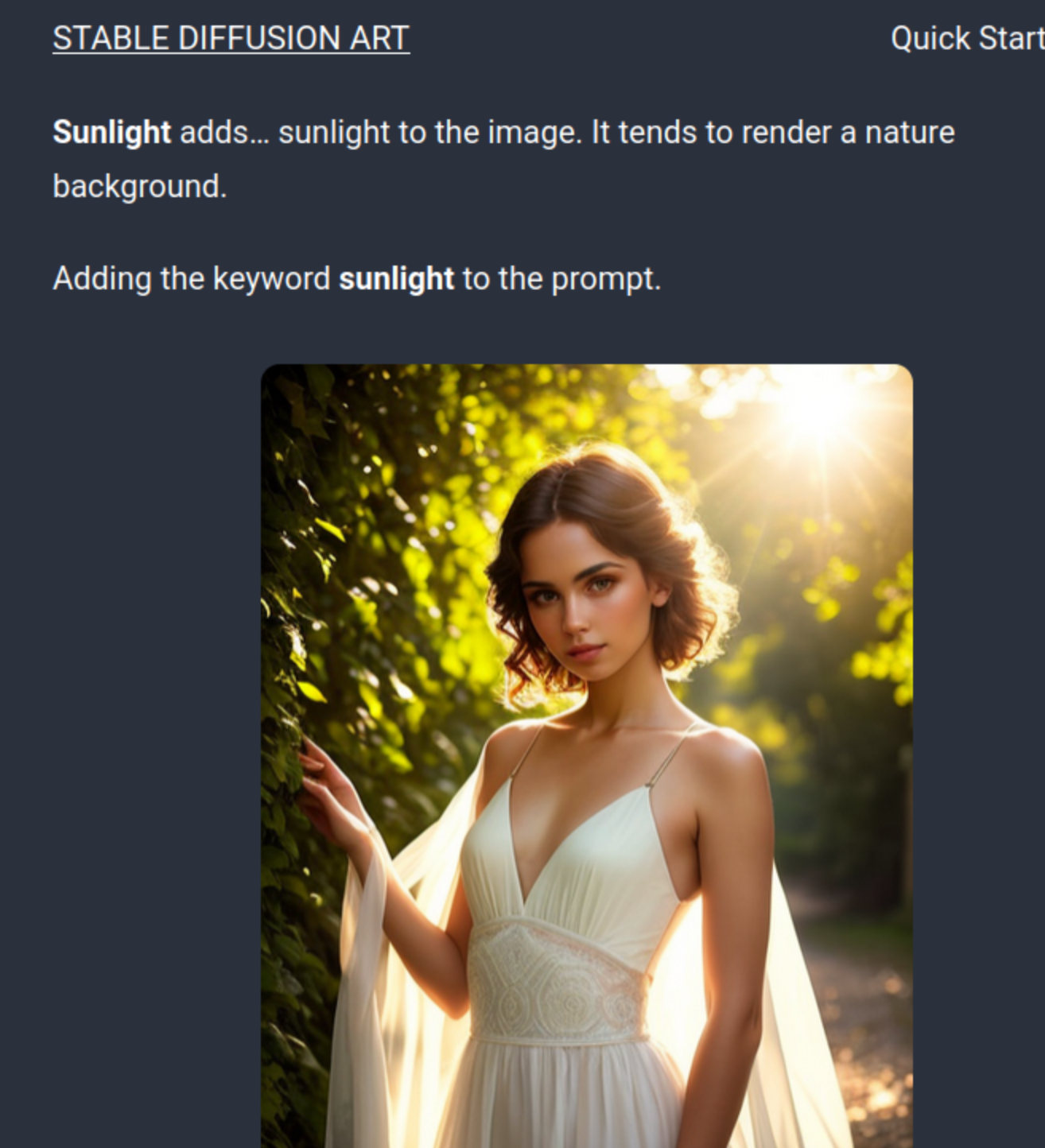
A small tweak to a prompt keyword intended to change just the lighting like 'sunlight' will change a background from bricks to plants, even though sunlight falls as easily on bricks as it does on plants. Once again, the model's behavior is non-local: changing anything changes everything.
The gigantic apparatus described by the a16z chart is an implicit admission that language models, as statistical text generators, intrinsically cannot be programmed. The type of control, monitoring, and separation of concerns that programmers like myself are accustomed to must be bolted on to them after the fact, with little guarantee that you can do so reliably. I have no interest in a tool that requires a devops and cloud software budget of a million dollars a year to operate safely.
Economic self-interest
An even more pragmatic reason why a creative practicioner may not want to use AI-based tools: you may not be able to claim copyright in the output. In the United States, the patent office has already indicated that the outputs of Midjourney in a published work do not enjoy copyright protection. If, as the patent office argues, there is "non-human authorship" at play, then you will have no way to protect your art against imitation and plagiarism. Indeed, I find it a little ironic that authors advising others to use these tools for little more than algorithmic likeness-based plagiarism are so keen on attempting to claim copyright for themselves.
I am, in general, no great fan of copyright, but it may be one of the few avenues left to artists to protect their interests against wholesale data theft. If you want to retain whatever modicum of control you can over your work, AI tools may be a legal minefield.
The irreducible labor of thinking
As far as ChatGPT and its utility for my own writing, Bjarnason said it far better than I could:
One aspect of writing that tends to get lost in all the discourse is that writing is thinking. The process of putting your thoughts into words is a form of reasoning that clarifies and condenses those thoughts. Writing is how I discover what matters to me. Writing is where I find out what I think.
This is why the first draft is often the hardest and why everybody dreads it. That’s the part where you dive into yourself and dredge up the truth itself.
Of course everybody wants to skip that.
I'd like to contrast this way of seeing writing with a meme that has become unfortunately fashionable among my political allies:

For better or for worse, I do dream of labor. I dream of the labor that I think is worth doing, and that I enjoy: the labor of making sense of the world, of acting within it to make it better, of trying, and failing, and trying again, to put the line in a place that correctly represents human anatomy, of participating in ecological remediation that helps us prepare for the climate of the next century, of building tools that can help scientists and workers reduce our dependencies on resources that require destructive extraction from beneath the earth.
Physical labor, as long as we have the organization necessary to prevent it from becoming back-breaking, can make us stronger in body. Intellectual labor, as long as we have the organization necessary to prevent it from becoming a mentally deadening bullshit job, can make us stronger in mind. I dream, as someone else once did, of a world where participation on both kinds of labor creates an "association, in which the free development of each is the condition for the free development of all."
A world "where nobody has one exclusive sphere of activity but each can become accomplished in any branch he wishes, society regulates the general production and thus makes it possible for me to do one thing today and another tomorrow, to hunt in the morning, fish in the afternoon, rear cattle in the evening, criticise after dinner, just as I have a mind, without ever becoming hunter, fisherman, herdsman or critic."
No AI model will save me from the intellectual and political labor required to bring us closer to that world.